This post will present another, useful feature of the AWS CLI tool set, the –filter parameter. This command line parameter is available and extremely helpful in EC2 namespace (aws ec2 describe-*).There are various ways to use –filter parameter.
1. –filter parameter can get filtering properties directly from the command line:
|
1 |
aws ec2 describe-instances --filter Name="instance-id",Values="i-1234abcd" |
2. –filter parameter will also use JSON-encoded filter file:
|
1 |
aws ec2 describe-instances --filters file://filters.json |
The filters.json file uses the following structure:
|
1 2 3 4 5 6 7 8 9 10 |
[ { "Name": "instance-type", "Values": ["m1.small", "m1.medium"] }, { "Name": "availability-zone", "Values": ["us-west-2c"] } ] |
There are various AWS CLI components that provide –filter parameters. For additional information check the References section.
To demonstrate the way this functionality can be used in various scenarios, there are several examples:
1. Filter by availability zone:
|
1 |
aws ec2 describe-instances --filter Name="availability-zone",Values="us-east-1b" |
2. Filter by security group (EC2-Classic):
|
1 |
aws ec2 describe-instances --filter Name="group-name",Values="default" |
3. Filter by security group (EC2-VPC):
|
1 |
aws ec2 describe-instances --filter Name="instance.group-name",Values="default" |
4. Filter only spot instances
|
1 |
aws ec2 describe-instances --filter Name="instance-lifecycle",Values="spot" |
5. Filter only running EC2 instances:
|
1 |
aws ec2 describe-instances --filter Name="instance-state-name",Values="running" |
6. Filter only stopped EC2 instances:
|
1 |
aws ec2 describe-instances --filter Name="instance-state-name",Values="stopped" |
7. Filter by SSH Key name
|
1 |
aws ec2 describe-instances --filter Name="key-name",Values="ssh-key" |
8. Filter by Tag:
|
1 |
aws ec2 describe-instances --filter "Name=tag-key,Values=Name" "Name=tag-value,Values=string" |
9. Filter by Tag with a wildcard (‘*’):
|
1 |
aws ec2 describe-instances --filter "Name=tag-key,Values=MyTag" "Name=tag-value,Values=abcd*efgh" |
10. Filter by multiple criteria (all running instances with string ’email’ in the value of the Name tag):
|
1 |
aws ec2 describe-instances --filter "Name=instance-state-name,Values=running" "Name=tag-key,Values=Name" "Name=tag-value,Values=*email*" |
11. Filter by multiple criteria (all running instances with empty Name tag);
|
1 |
aws ec2 describe-instances --filter "Name=instance-state-name,Values=running" "Name=tag-key,Values=Name" "Name=tag-value,Values=''" |
Those examples are very close to production ones used in several large AWS deployments. They are used to:
- Monitor changes in instance populations;
- Monitor successful configuration of resources;
- Track deployment / rollout of new software version;
- Track stopped instances to prevent unnecessary resource usage;
- Ensure desired service distributions over availability zones and regions;
- Ensure service distribution over instances with different lifecycle;
Be sure to utilize this functionality in your monitoring infrastructure. It has been powerful source of operational insights and great source of raw data for our intelligent control planes!
If you want to talk more on this subject or just share your experience, do not hesitate to Contact Us!
References
- http://docs.aws.amazon.com/cli/latest/reference/ec2/describe-instances.html
- http://docs.aws.amazon.com/cli/latest/reference/ec2/describe-spot-instance-requests.html
- http://docs.aws.amazon.com/cli/latest/reference/ec2/describe-reserved-instances.html
- http://docs.aws.amazon.com/cli/latest/reference/ec2/describe-network-acls.html
- http://docs.aws.amazon.com/cli/latest/reference/ec2/describe-key-pairs.html
- http://docs.aws.amazon.com/cli/latest/reference/ec2/index.html
Related Posts
- Small Tip: How to use –block-device-mappings to manage instance volumes with AWS CLI
- Small Tip: How to use AWS CLI to start Spot instances with UserData
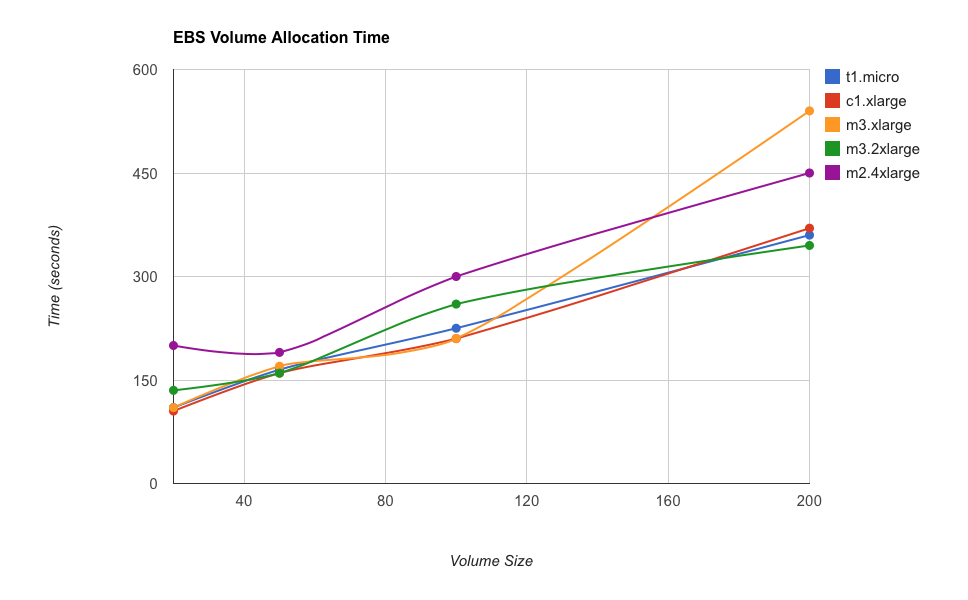
- Small Tip: EBS volume allocation time is linear to the size and unrelated to the instance type
- How to deploy single-node Hadoop setup in AWS
- UserData Template for Ubuntu 14.04 EC2 Instances in AWS